拉勾网广州地区近一个月282个运维招聘信息分析
写在前面
我抓取了 拉勾网 一个月内发布的职位关键字为 运维 ,地区为 广州 的 282 个招聘需求信息,并在此基础上做了一些图表分析。
纯为技术研究,没别的意思,领导和 HR 看了不要找我聊天。
不喜看脚本的,可直接拉到下方看图。
数据抓取
拉勾网的前端非常工整,招聘信息无需登录即可获取,比起 智联招聘 和 中华英才网 那种到处贴广告的不知所谓的页面来说简直是业界良心。对于不需要登录即可获取信息的表层网络,抓取数据什么语言顺手就用什么语言。对于我来说,还是用 curl 和 grep / sed 比较方便,写个十来行就行,够 Python 写几十行了。
抓取页面为 https://www.lagou.com/zhaopin/yunwei/${page}/,从第 1 页到第 19 页。
GET 方式,地区识别放在了 cookies 里,所以 curl 请求的时候需要设置 cookies ,最简单的方式是打开浏览器的调试工具,使用 Copy as cURL ,如下图:
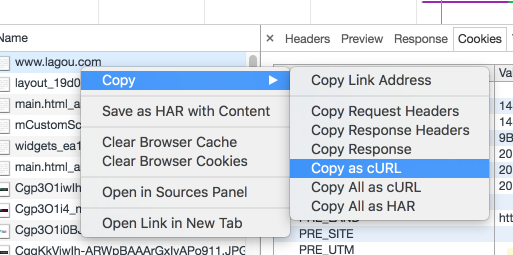
cookies 中的 index_location_city 即是用户的地区信息。
每个页面中有 15 条招聘信息,结构是这样的:

在需求岗位的旁边有标注了上班地段,这个是需要分析的一项,因此也要抓下来。看下 html ,是长这样的:
<span class="add">[<em>珠江新城</em>]</span>
每项都有一个对应的 class ,抓取就容易了:
grep -Po '(?<=<span class="add">\[<em>).*?(?=</em>\]</span>)' "${html}"
职位页面的链接,也可以直接用 grep -Po 匹配:
<a class="position_link" href="//www.lagou.com/jobs/1643110.html" ... >
得到链接后,进入职位页面,这里要用 curl 的 -L 选项,否则只能抓到 302 的跳转页面。职位页面有两段需要截取的内容:

使用 sed 截取
sed -rn '/position-content-l/,/position-content-r/{s/<[^>]+>//g;s/^\s+//g;/^\s*$/d;p}' <<< "${job_html}"
另外一段详细职位需求的,也如法炮制。
一个职位页面,获取到的信息如下:
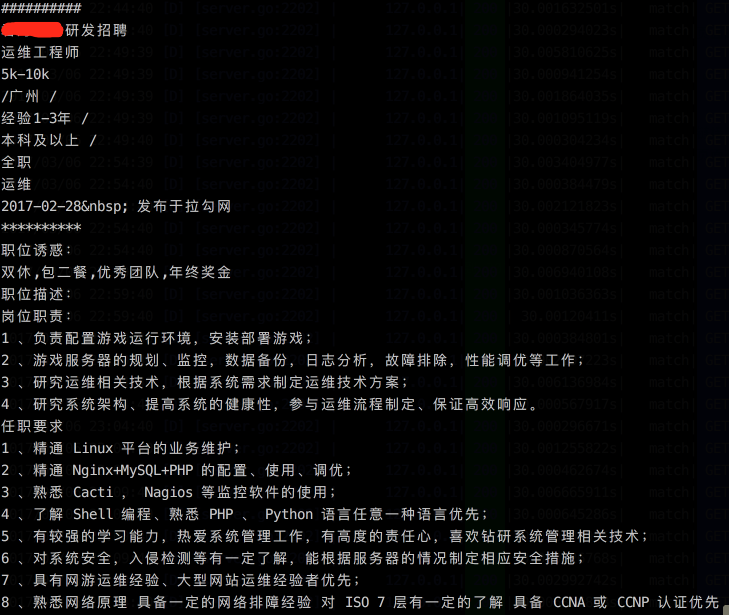
每抓完一个页面后,sleep 上个几秒,要尊重被抓取的网站,不要给人家服务器造成压力,虽然人家极有可能一点都不在乎你这三百个请求。
两层 for ,共十二行,开抓。
喝杯水,看会电视,发现已搞定,得到一个 355K 的文本。
整理数据
结合上图,根据要分析的内容,分为了以下 5 部分:
- 上班地段:在抓取时格式已经非常工整,无需额外处理;
- 职位要求学历:也比较工整;
- 职位诱惑:就是一些招聘单位自夸的 tag ,中间夹了好多标点符号要处理成空格,意思相同但字眼不同的尽量修改统一 (比如 年底双薪 和 年终双薪);
- 任职要求:直接取出英文字符并统一转为小写,比如 shell / python 这些 IT 技能;
- 岗位职责:貌似没多大意思,可以先用 jieba 把词分好,后面看下是否可以用 标签云 的方式展现出来;
- 经验年限和薪资:这两项应该是相关联的,需要一起处理。
分析绘图
用了 jupyter 和 plotly ,有兴趣的同学可以参考下面两个网址安装下试试:
- http://jupyter.readthedocs.io/en/latest/install.html
- https://plot.ly/python/ipython-notebook-tutorial/
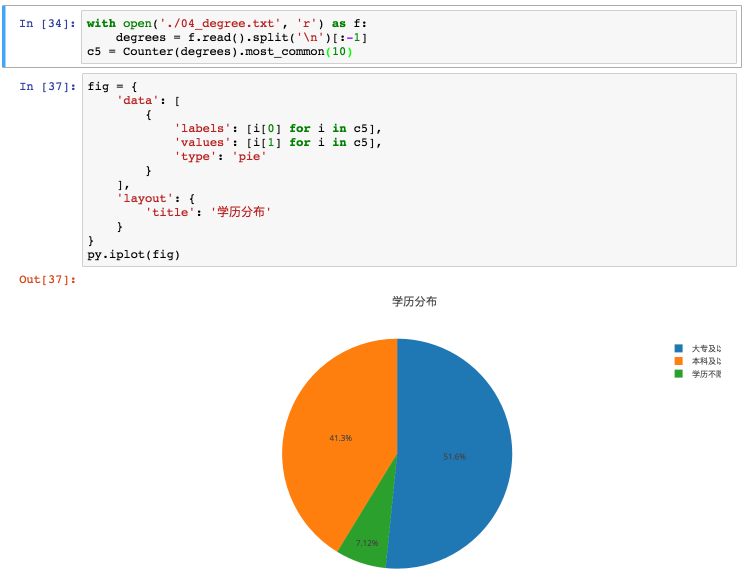
数据的读入和列表化:数据量少,直接用了 collections.Counter 。
以下是一个例子:
一些图表
终于到了大家最感兴趣的部分了。
上班地段
先来看下招聘的上班地段分布:(取前 50 名)
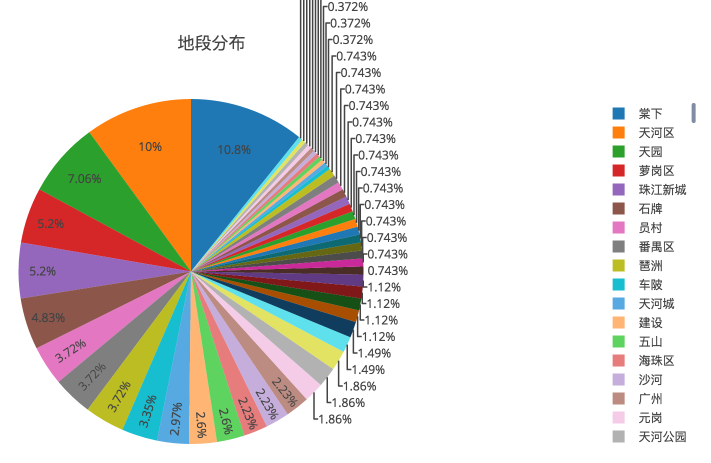
75% 以上都是在天河。而天河的职位基本都在 珠江新城 -> 石牌 -> 棠下 -> 车陂 一带。
壮哉,我大天河!要找运维狗,请到科韵路。
职位诱惑
看看这些公司招运维狗的时候都喜欢标榜自己公司什么优势:
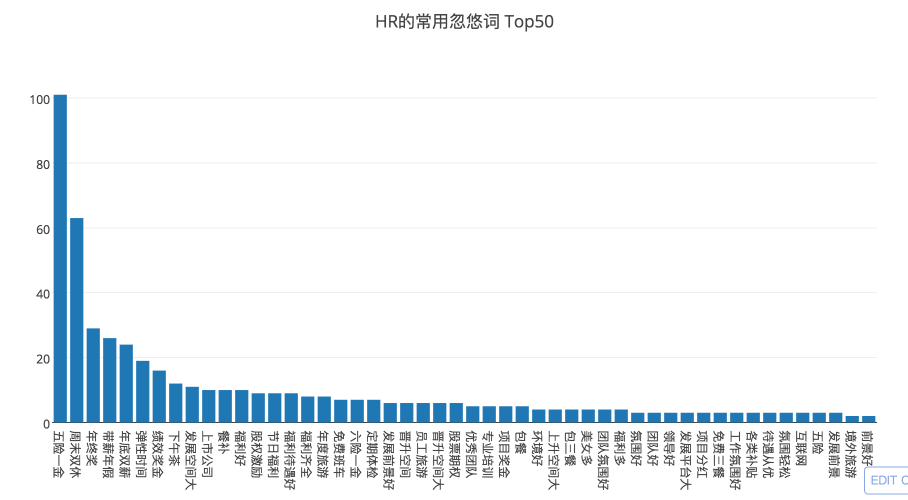
第一名是 五险一金 ,超过 1/3 的公司都提到了,我很好奇其他的 2/3 的公司是不是没有五险一金;
然而第二名是 周末双休 , 这他喵的都成职位优势了,可见双休对多数运维狗来说是多么奢侈;
表示自己有 弹性时间 的也不少,这是互联网行业的黑话,说明你丫的别想有加班补贴;
其他的什么 发展空间、期权、福利 之类的画饼的就不多说了,还有 4 家公司号称自己公司 美女多 ,估计是 HR 编不下去然后照下镜子昧着良心填上去的。
学历分布
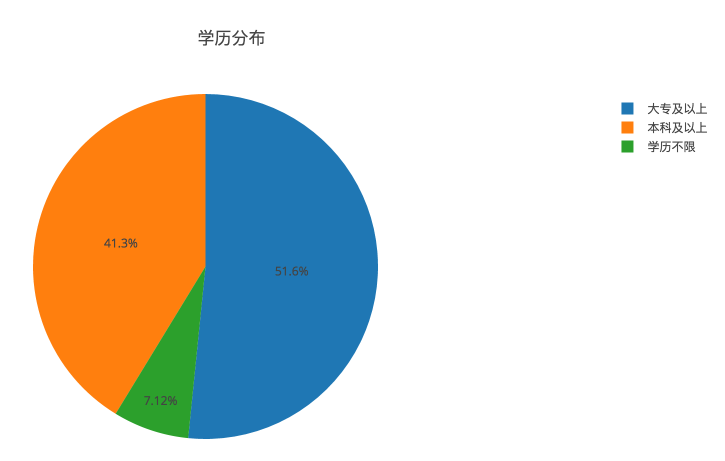
运维 号称 IT 行业里门槛最低的岗位,不是没有道理的。
薪酬水平
鉴于开出的类似于 15k-25k 这样的数字,我们都知道,只要参考低的那个值就可以了。
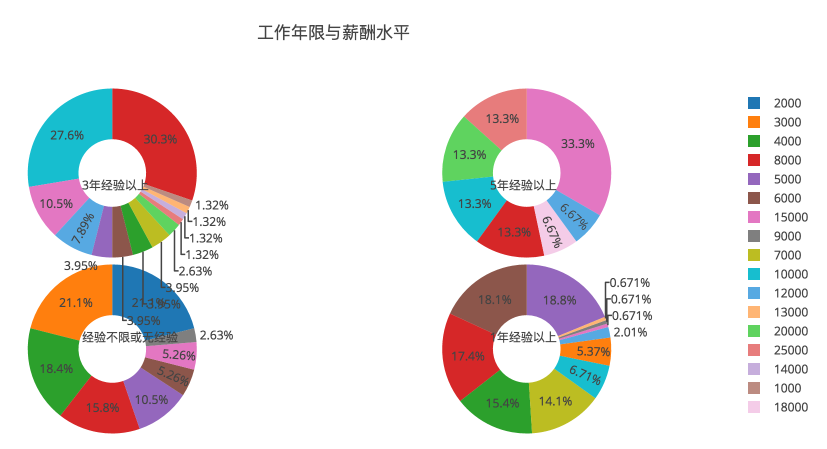
无经验其实跟 1 年经验起薪差别并不大,而 3 年经验起码有 50% 可以 8k 起薪,5 年经验 50% 可以 1w 起薪。
联系到上面的学历分布,肯定有同学会说,不如读个大专,早点出去工作,赚工作经验呢。
这倒未必,请看下图:
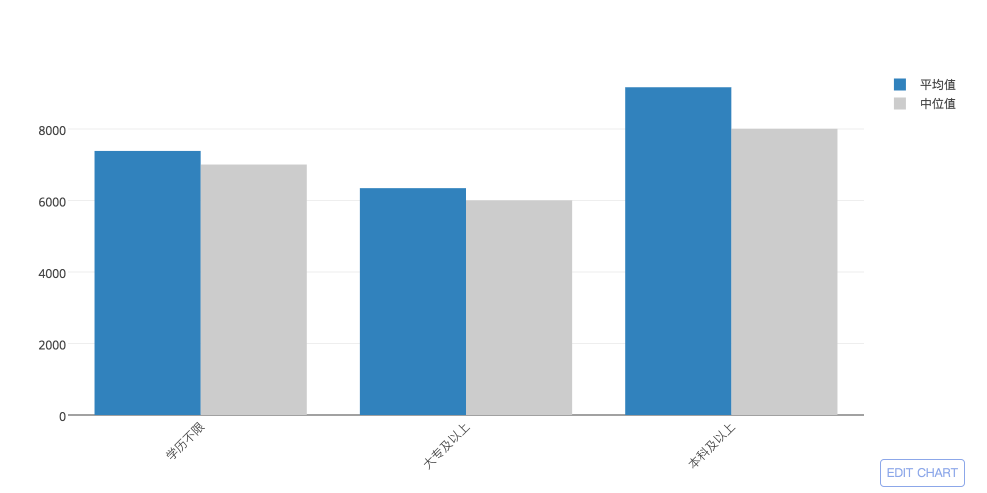
数据证明,本科的平均起薪还是比大专要高的。
SKILLS
最后看下运维狗所需的技能 ( Top 50 ):
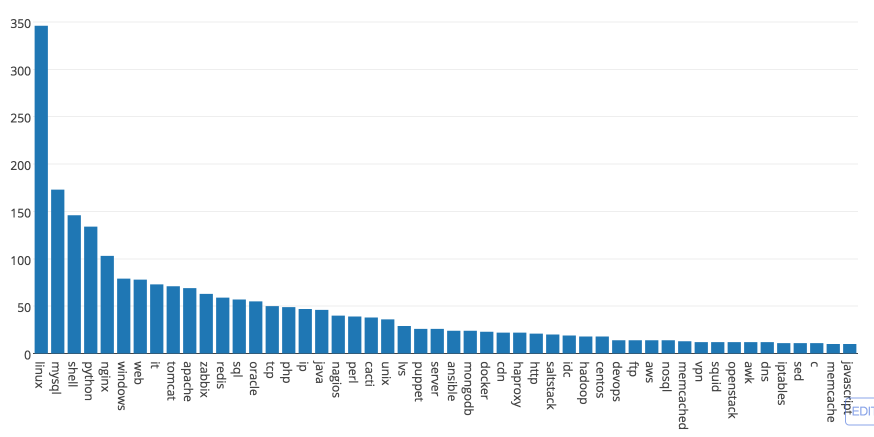
操作系统方面,Linux 遥遥领先于 Windows 和 Unix ,以及其他所有术语,这个是运维狗的根基;
语言方面,Shell 和 Python 这对老基友当仁不让是运维狗的最爱,SQL 和 世界上最好的语言 PHP 紧随其后,Java 和 Perl 的需求也不低,sed / awk 和 C 在长尾的最后露个小脸;
数据库方面,MySQL 还是老大,Oracle 紧跟其后;NoSQL 中,redis 和 mongodb 已经远胜 memcached ;
监控平台,Zabbix 一枝独秀,Nagios 和 Cacti 也有一定的量;
Web 方面,还是 Nginx 比 Apache 牛逼,tomcat 都比 Apache 提到的次数多;LVS 和 HAProxy 提到的数量也不少;
运维管理工具方面,Puppet / Ansiable / SaltStack 基本上算是并驾齐驱;
最后,目前热门的新兴技术,比如 Hadoop 为代表的大数据、Docker 和 OpenStack 为代表的虚拟化,提到的次数都不算多,说明整个广州运维行业,发展还是比较缓慢的。
总而言之,作为运维狗,上面的技术或多或少都要接触下。
写在最后
祝各位运维狗少背锅,多赚钱!