bosun是一个基于openTSDB的一个监控系统,它在openTSDB基础上增加了报警系统,解决了openTSDB只能看不能报警的弱点。
本文章只是简单记录了如何安装bosun(官网上的QuickStart只有用docker来部署的例子),及简单的监控项部署介绍。
HBase和openTSDB
bosun基于openTSDB,所以需要安装HBase和openTSDB,要快速部署,推荐使用CDH,安装步骤可参考我之前的几篇文档。
go
bosun是用go写的,这里我直接用了bosun的二进制版本,不依赖go。但如果要编译安装bosun,需要先安装go,具体方法可以参考go官网(需翻墙)。
bosun
下载安装:
mkdir /opt/bosun
wget -c https://github.com/bosun-monitor/bosun/releases/download/0.4.0/bosun-linux-amd64 -O bosun-linux-amd64
chmod 755 bosun-linux-amd64
echo 'tsdbHost = localhost:4242' > bosun.conf
./bosun-linux-amd64 -c bosun.conf
也许可能会看到以下的报错:
2015/12/09 14:34:33 error: queue.go:87: 400 Bad Request
2015/12/09 14:34:33 error: queue.go:93: {"error":{"code":400,"message":"One or more data points had errors","details":"Please see the TSD logs or append \"details\" to the put request","trace":"net.opentsdb.tsd.BadRequestException: One or more data points had errors...
然后查看openTSDB的日志,发现以下的信息:
14:34:18.445 WARN [PutDataPointRpc.execute] - Unknown metric: metric=bosun.schedule.lock_time ts=1449642856 value=0 caller=RestoreState host=nn op=wait
这个是由于openTSDB没有开启自动增加metric的功能导致bosun没法添加metric。
修改openTSDB配置,将tsd.core.auto_create_metrics的值改为true,然后重启TSDB,可以解决问题。
页面访问
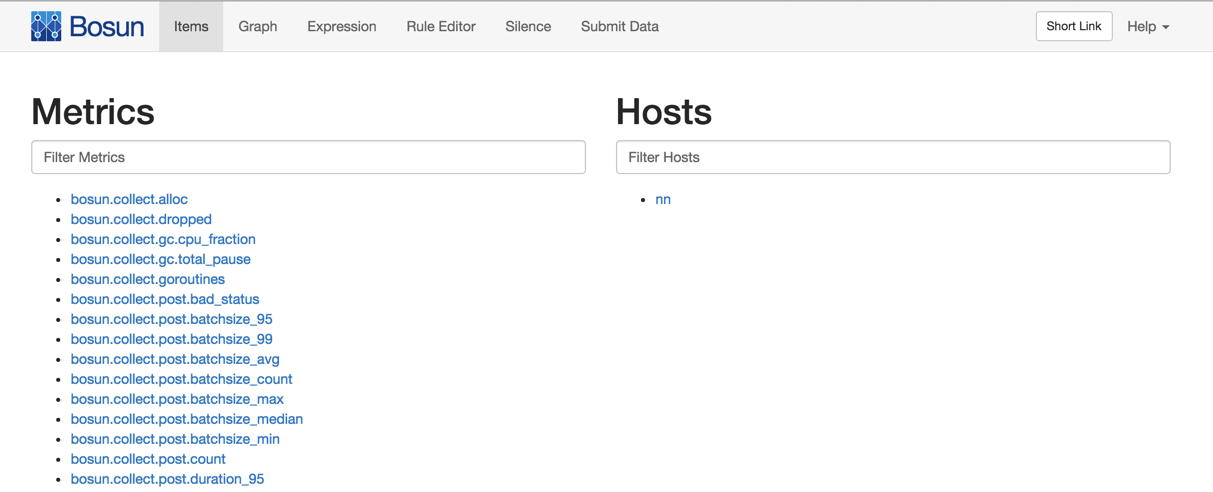
可以看到bosun本身也自带了非常多的监控项。
scollector
用scollector作为客户端向bosun提交数据。
安装:
mkdir /opt/scollector
cd /opt/scollector
wget -c https://github.com/bosun-monitor/bosun/releases/download/0.5.0-alpha/scollector-linux-amd64 -O scollector-linux-amd64
chmod 755 scollector-linux-amd64
./scollector-linux-amd64 -h="nn.mc.com:8070" -d
-h的参数是bosun的域名或ip及端口。
-d是开启debug信息。
运行后我们在页面中的Hosts列就可以看到新加入的机器了。
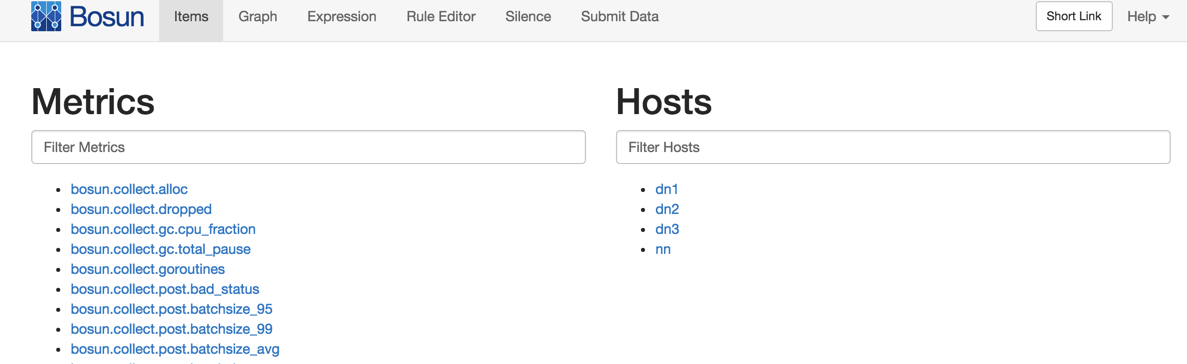 scollector具有自动发现服务的能力,比如开启了ntp服务,它就自动增加了ntp的监控项。而且scollector自带的系统监控项都已经有上百个了,非常详尽!
scollector具有自动发现服务的能力,比如开启了ntp服务,它就自动增加了ntp的监控项。而且scollector自带的系统监控项都已经有上百个了,非常详尽!
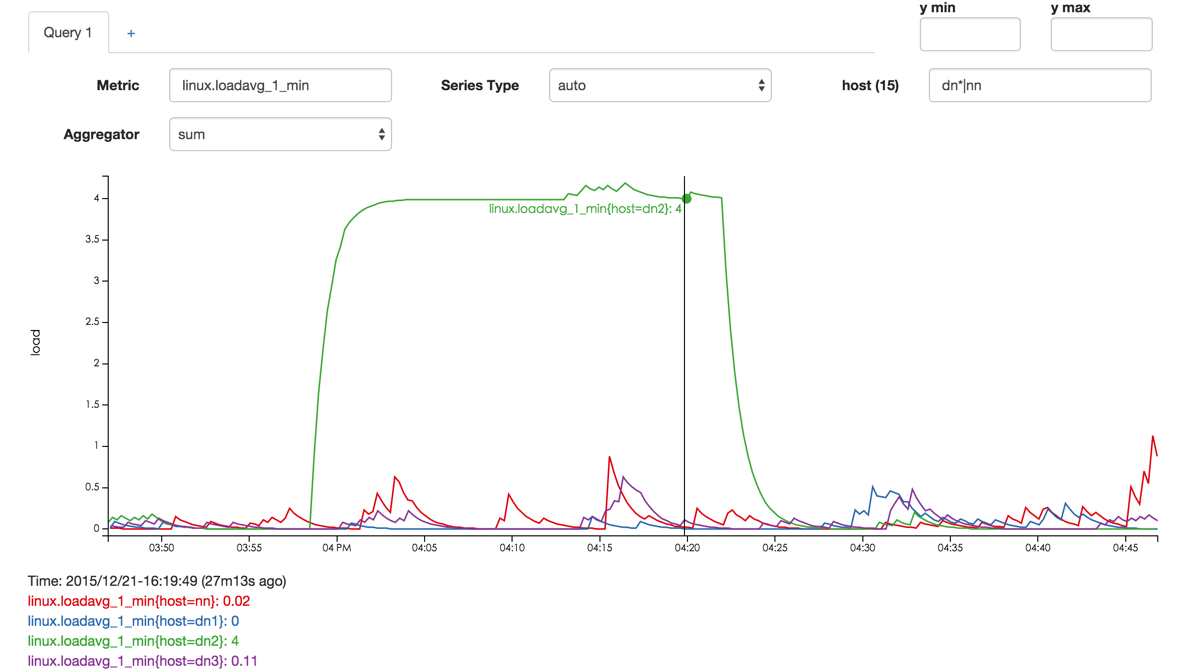
另外再提个重要的一点,bosun支持tag的通配符和或操作查询,这个是openTSDB所不具备的功能,请看下图的host框:
邮件报警设置
bosun提供了多种报警方式,叫做actions,除了email方式,还有POST和GET(可以与我们的微信报警结合)。这里先介绍下email报警设置。
要发邮件,以下的一些邮件账号信息是必须的:
smtpHost = smtp.163.com:25
emailFrom = xxxxxxxx@163.com
smtpUsername = xxxxxxxx
smtpPassword = yyyyyyyy
还需要有个邮件的模板:
template alarm {
subject = {{.Last.Status}}: {{.Alert.Name}} on {{.Group.host}}
body = `<p>Name: {{.Alert.Name}}
<p>Value: {{.Alert.Vars.q}}
<p>Tags:
<table>
{{range $k, $v := .Group}}
<tr><td>{{$k}}</td><td>{{$v}}</td></tr>
{{end}}
</table>`
}
还要有个notification,个人理解是用来给actions调用的通知方式:
notification email {
email = aaaaaaaa@163.com
next = email
timeout = 10m
}
email项设置的是接收报警邮件的邮箱地址。next指定了如果在timeout规定的时间内还没有Acknowledge所需要操作的动作。意思是10分钟内还没有人去处理(即Acknowledge)则再发一次告警邮件。
触发报警的流程:
alert mem {
template = alarm
$q = avg(q("sum:linux.mem.memfree{host=*}", "1m", ""))
crit = $q < 102400
critNotification = email
}
上面设置了如果Linux系统的空余内存少于102400k(即100M)则触发报警级别为crit的动作。
修改配置文件后,重启下bosun,如果有能触发报警的在监控机器,你就会收到这样的报警邮件:
 上图是一台macmini的磁盘报警邮件。
上图是一台macmini的磁盘报警邮件。
关于邮件的模板,还可以嵌入图表,如:
template alarm {
subject = {{.Last.Status}}: {{.Alert.Name}} on {{.Group.host}}
body = `<p>Alert: {{.Alert.Name}} triggered on {{.Group.host}}
<hr>
<p><strong>Computation</strong>
<table>
{{range .Computations}}
<tr><td><a href="{{$.Expr .Text}}">{{.Text}}</a></td><td>{{.Value}}</td></tr>
{{end}}
</table>
<hr>
{{ .Graph .Alert.Vars.metric }}
<hr>
<p><strong>Relevant Tags</strong>
<table>
{{range $k, $v := .Group}}
<tr><td>{{$k}}</td><td>{{$v}}</td></tr>
{{end}}
</table>`
}
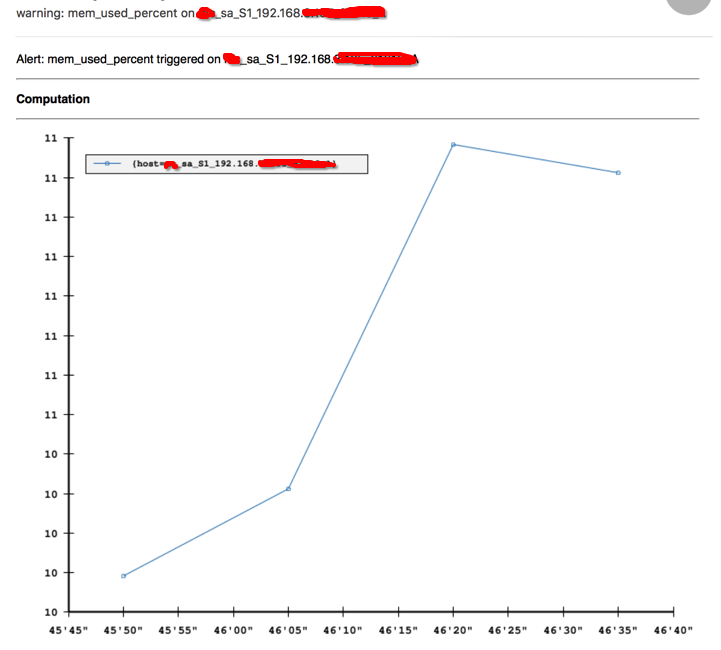
上面template中的{{ .Graph .Alert.Vars.metric }}就是嵌入的图,这里的metric指的是在alert段中配置的metric变量,如下:
alert mem_used_percent {
template = alarm
$metric = q("sum:os.mem.percent_free{host=*}", "1m", "")
$q = 100 - avg($metric)
warn = $q > 80
crit = $q > 90
warnNotification = email
critNotification = weixin
}
注意,要能显示图,metric必须是个q函数,另外如果alert中没有该变量,则是一个空白的图。
嵌入图的报警邮件如下:
External Collectors
不同的业务系统,所需要监控是不一样的,因此,如果bosun默认自带的监控项并不能满足我们监控特定业务的需求,则需要有个External Collectors的机制去完成我们的需要。
External Collectors的实现方式跟tcollector一样,只要是有可执行权限的程序,可以在stdout上输出以下的格式即可(所以你可以用各种你熟悉的语言去编写collector):
Metric Timestamp Value Tags
其中Tags是可选的,host这个tag是自动添加上去的,可以不在collector里显式输出。
以下是假设有个msalt的应用,我们监控下该进程的CPU和内存占用百分比,用简单的shell来写。
先设置目录:
# 目录里的数字目录,表示多少秒执行一次collector
# 如这里的15,表示15秒执行一次
mkdir -pv /opt/scollector/collectors/15
touch /opt/scollector/collectors/15/msalt.sh
chmod 755 /opt/scollector/collectors/15/msalt.sh
msalt.sh脚本:
#!/bin/bash
psinfo=$(ps aux | /bin/grep '[m]salt-common')
cpu_percent=$(awk '{print $3}' <<< "${psinfo}")
mem_percent=$(awk '{print $4}' <<< "${psinfo}")
echo "app.msalt.cpu_percent `date +%s` ${cpu_percent}"
echo "app.msalt.mem_percent `date +%s` ${mem_percent}"
添加个scollector.toml配置文件,内容如下:
hostname = "S1_192.168.xx.xx"
ColDir = "/opt/scollector/collectors"
最后启动scollector
cd /opt/scollector
./scollector-linux-amd64 -conf="scollector.conf" -h="nn.mc.com:8070"
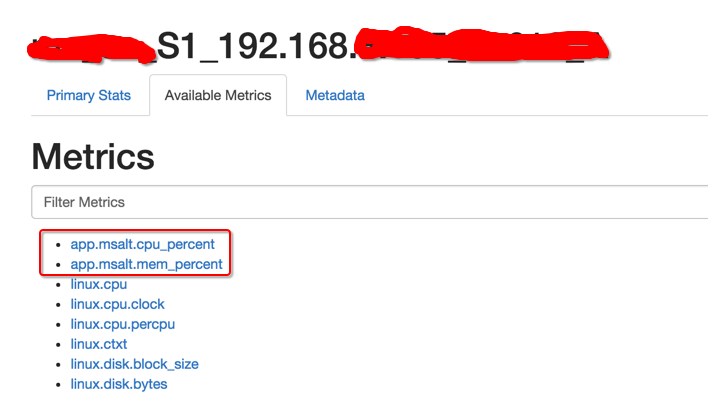
可以看到External Collectors添加的metric:
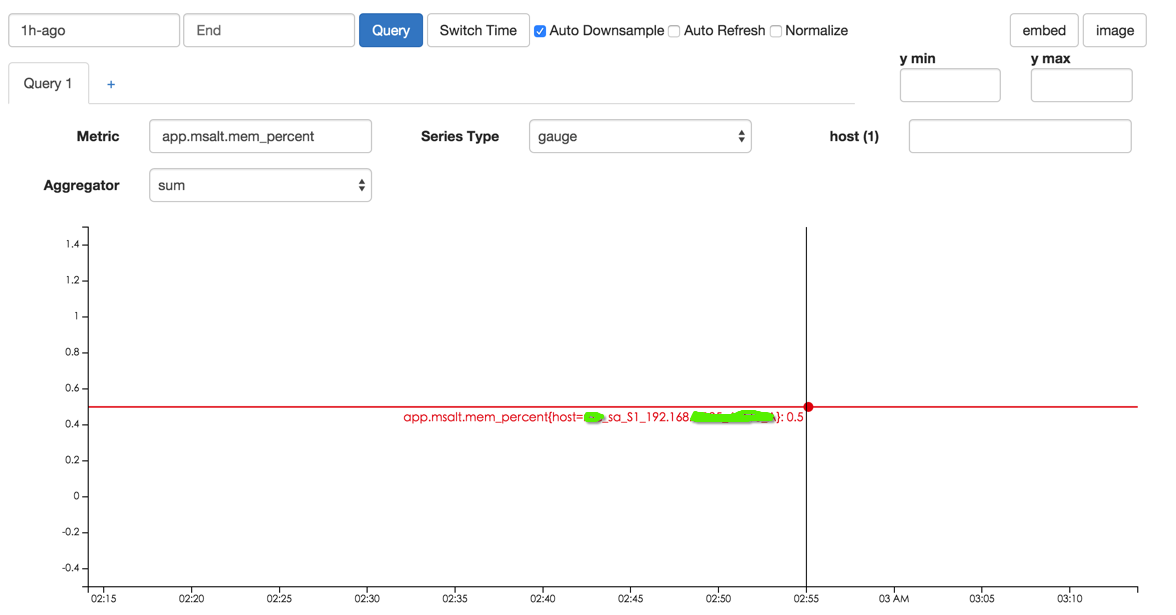
Graph:
监控项表达式
bosun的监控项表达式非常灵活,可以自定义多种监控报警方式。当然,非常灵活的代价就是比较难配置。
举个例子,在实际应用中,很多监控项都是百分比数值。比如说磁盘利用率达到85%,再比如说剩余内存只有10%,等等。我们可以利用bosun里的alert配置复杂的表达式求值。
下面这个例子是磁盘空间利用率的alert:
alert linux_disk_used_percent {
template = alarm
$metric = q("sum:linux.disk.fs.space_used{host=*,mount=*}", "1m", "")
$used = avg($metric)
$total = avg(q("sum:linux.disk.fs.space_total{host=*,mount=*}", "1m", ""))
$q = ($used / $total) * 100
warn = $q > 80
crit = $q > 90
warnNotification = email
critNotification = weixin
}
再举个例子,平常我们关注系统的负载,一般是看负载是否超过CPU核数,因此每台机器的负载监控阀值是不一样的。比如说,对于一个4核的机器来说,负载达到8算是高负荷了,而对于16核的机器,则是低负荷。如果要设置一个统一的阀值,则应该是loadavg/cpu_num。在bosun上实现,非常简单:
alert linux_loadavg_1min {
template = alarm
$metric = q("sum:linux.loadavg_1_min{host=*}", "1m", "")
$loadavg = max($metric)
$cpu_num = avg(q("sum:rate{counter,,1}:linux.cpu.percpu{host=*}", "1m", ""))
$q = 100 * $loadavg / $cpu_num
warn = $q >= 0.8
crit = $q >= 1
warnNotification = email
critNotification = weixin
}
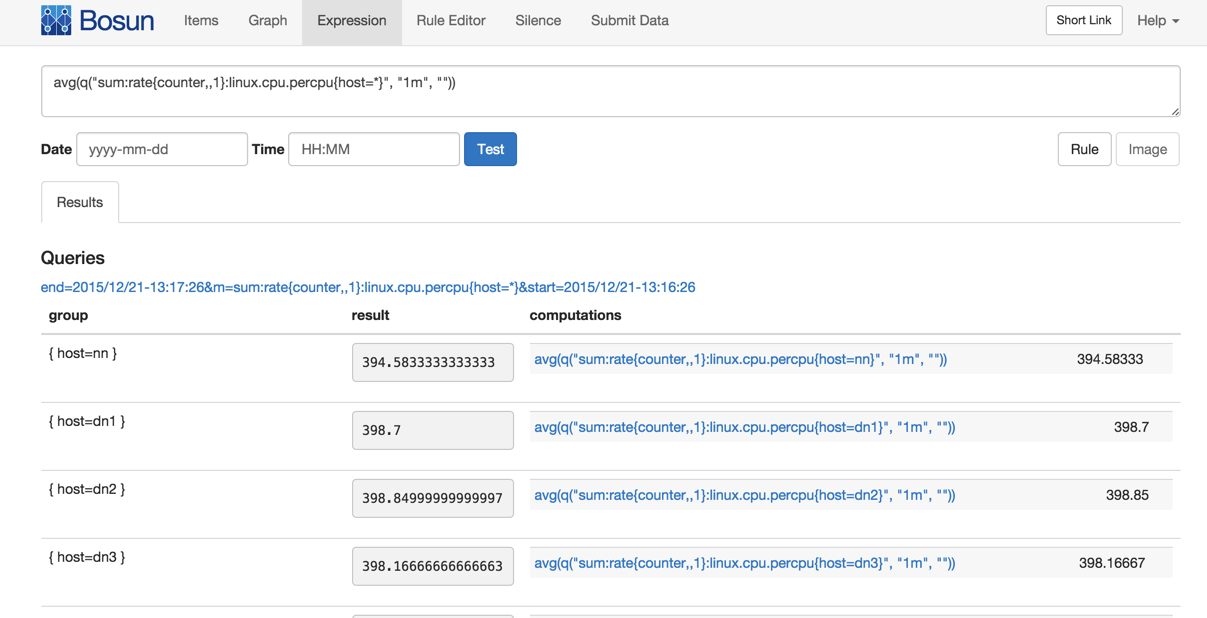
这里,sum:rate{counter,,1}:linux.cpu.percpu{host=*}会把一个监控主机的所有CPU时间(system,user,idle,iowait,nice,irq,softirq)相加起来,接近于CPU核数*100,于是就可以求出loadavg/cpu_num的比值:
notifation的POST json设置
bosun的notifation提供了POST和GET方式。以我们在使用的微信报警接口为例,我在bosun机器上部署了简单的openresty服务,其中/wx接口采用GET提交u和m两个变量(u变量是用户名,而m变量则是要发送的message),而/wx2接口则是POST方式,接收的是json,如
{"u":"zhengheng", "m":"ok"}
如果使用GET,设置个url即可,如:
notification weixin {
post = http://localhost/wx?u=zhengheng&m=CheckYourEmailPlease
next = weixin
timeout = 10m
}
但是在url中无法设置变量。
POST json方式:
notification weixin {
post = http://localhost/wx2
body = {"u": "zhengheng", "m": {{.|json}}}
contentType = application/json
next = weixin
timeout = 5m
}
{{.|json}}是告警标题的json格式化。

alert中的log模式
目前为止,我们所设置的告警只通过notification设置的方式发送告警两次,之后想查看历史告警,都要上bosun的dashboard页面查看或通过它的API去查询。但在实际应用场景中,有时我们会希望该告警不止通知两次,而是如果告警没消除,则隔段时间又发一次通知,直到告警被处理为止(传说中的“呼死你”)。在bosun中可以这么设置:
notification email_log {
email = aaaaaaaa@163.com
}
notification weixin_log {
post = http://localhost/wx3
body = {"u": "zhengheng", "m": {{.|json}}}
contentType = application/json
}
alert linux_loadavg_1min {
log = true
maxLogFrequency = 5m
template = alarm
$metric = q("sum:linux.loadavg_1_min{host=*}", "1m", "")
$loadavg = max($metric)
$cpu_num = avg(q("sum:rate{counter,,1}:linux.cpu.percpu{host=*}", "1m", ""))
$q = 100 * $loadavg / $cpu_num
warn = $q >= 0.8
crit = $q >= 1
warnNotification = email_log
critNotification = weixin_log
}
log = true:开启log模式;maxLogFrequency = 5m:5分钟检查一次,如仍有触发告警的条件则发送告警;- 所调用的
notification中不能有next和timeout。
lookup
设置lookup的一个作用是可以排除某些特别的机器。
比如有台机器负载已知是非常高的,可以忽略,我们可以在lookup里给它设置个非常大的阀值:
lookup load {
entry host=*highload* {
warn_value = 80.0
crit_value = 100.0
}
entry host=* {
warn_value = 0.8
crit_value = 1
}
}
然后在alter中使用lookup:
alert linux_loadavg_1min {
log = true
maxLogFrequency = 5m
template = alarm
$metric = q("sum:linux.loadavg_1_min{host=*}", "1m", "")
$loadavg = max($metric)
$cpu_num = avg(q("sum:rate{counter,,1}:linux.cpu.percpu{host=*}", "1m", ""))
$q = 100 * $loadavg / $cpu_num
warn = $q >= lookup("load", "warn_value")
crit = $q >= lookup("load", "crit_value")
warnNotification = email_log
critNotification = weixin_log
}
值得注意的是,被监控主机在lookup中是至上往下去寻找第一条符合条件的项,所以像上面的排除某台机器的应用场景,应该将排除主机写在lookup的开头。